
MuleSoftのIntelligent Document Processing(IDP)は、物理的な文書からデータの抽出、処理、分析を自動化することを可能にします。機械学習と自然言語処理を活用することで、IDPはPDF、画像、スキャン文書などの非構造化データを、業務プロセスにシームレスに連携できる構造化されたデータに変換します。

Mule IDPは、Amazon Textractを活用してドキュメントからデータを抽出します。一方、Einstein AIは、提供されたプロンプトに基づいてコンテンツ分析を行います。抽出された情報は、構造化されたフォーマット(JSONなど)に変換され、お客様の業務ワークフローにシームレスに連携されます。

このプロセスの設定は「ドキュメントアクション」と呼ばれ、さまざまな抽出ニーズに合わせてカスタマイズできます。設定が完了すると、ドキュメントアクションはMuleSoft Exchangeに公開され、RESTful APIを通じてアクセスしたり、Anypoint StudioやRPA Builderなどのアプリケーションを使用することで、さらなる自動化を推進することができます。
詳しくは、「IDPとAnypoint Studioの連携」および「RPAによるドキュメント処理の自動化」を参照してください。
従来の光学式文字認識(OCR)ツールは、文書からのデータ抽出に広く使用されてきましたが、データ抽出の前に文書領域の選定と範囲設定が必要となります。 一貫したテンプレートを持たない流動的な文書を扱う場合、OCRソリューションはテンプレートごとに学習させる必要があり、多大なメンテナンスが必要となります。
MuleSoftのIntelligent Document Processing(IDP)は、あらゆる文書の中から目的の情報を正確に特定するように学習した人工知能(AI)の一種である大規模言語モデル(LLM)の文書分析と抽出機能を活用することで、OCRの域を超えるものとなっています。このアプローチでは、OCRと比較して保守を最小限に抑えることができます。一貫性のあるわかりやすいクエリにより、MuleSoft IDPは抽出前に特定の文書領域を設定する必要がなく、動的に必要な情報を特定することができます。
Demo: インボイス処理
MuleSoft IDPを使用することで、英語で記載された請求書からデータが抽出され、迅速な自動処理が可能になります。データ抽出の信頼性が低い場合は、手動での確認を行う選択肢も用意されています。
ドキュメントアクションの作成と公開
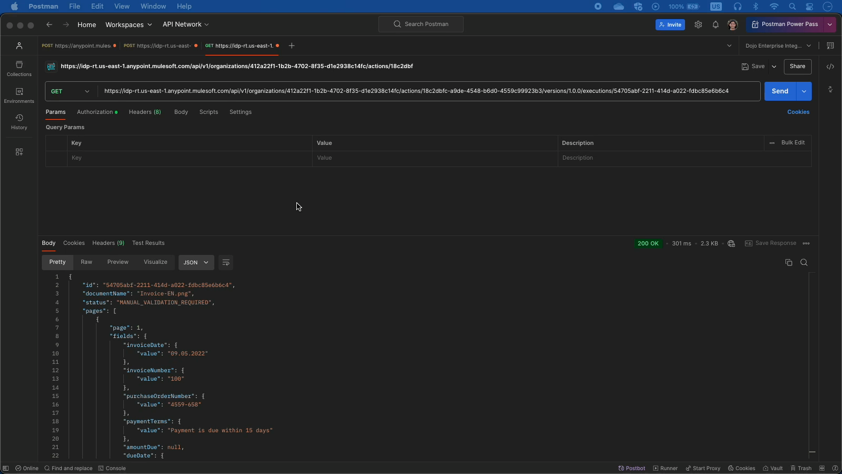
Exchangeアのの視覚化と、PostmanでのAPIコール
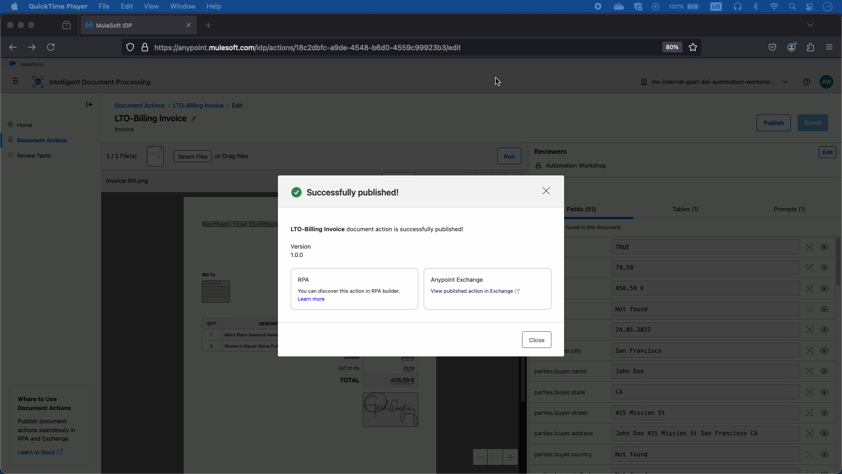
手動レビューの起動
IDPが抽出されたデータに対して十分な確信が持てない場合、さらなる検証のために手動でのレビューを起動することができます。
デモ: カスタムドキュメント処理 IDPは、ポルトガル語のドキュメントからの情報抽出に見られるように、複数の言語を処理することができ、ドキュメントに対して多様なニーズを持つグローバル企業にとって理想的なソリューションです。
ドキュメントアクションの作成と公開
Exchange資産の視覚化と、PostmanでのAPIコール
MuleSoftのIntelligent Document Processingソリューションは、お客様のドキュメントワークフローにスピード、正確性、セキュリティを提供します。このソリューションを導入することでいかに業務ワークフローを変革するか、またはお客様の企業におけるMuleSofが持つ可能性をいかに最大限に引き出せるか、MuleSoftサービスについてOSFまでお問い合わせください。
お客様の独自のニーズに合わせたSalesforceソリューションについて、ぜひご相談、お問い合わせください。免責事項:Northern Trail Outfittersは、この記事の説明目的で使用されている架空の会社です。