Qu'est-ce que MuleSoft Intelligent Document Processing ?
MuleSoft Intelligent Document Processing (IDP) permet aux entreprises d'automatiser l'extraction, le traitement et l'analyse des données à partir de documents physiques. En s'appuyant sur l'apprentissage automatique et le traitement du langage naturel, IDP transforme les données non structurées - telles que les PDF, les images et les documents numérisés - en données structurées qui peuvent être intégrées de manière transparente dans les processus d'entreprise.

Pourquoi utiliser MuleSoft Intelligent Document Processing ?
- Gagner en efficacité et libérer des ressources. L'automatisation du flux de traitement des documents réduit considérablement le temps et les efforts nécessaires pour traiter de gros volumes de documents. En utilisant l'IDP, les employés peuvent se concentrer sur des tâches plus stratégiques plutôt que sur la saisie de données qui prend du temps.
- Réduction des erreurs et augmentation de la précision. La saisie manuelle des données est sujette à des erreurs qui peuvent s'avérer coûteuses. L'IDP minimise ces erreurs en automatisant l'extraction et le traitement des données, ce qui garantit une précision et une fiabilité accrues.
- Évolutivité. MuleSoft IDP est conçu pour traiter de gros volumes de documents, ce qui en fait une solution idéale pour les entreprises de toutes tailles. Qu'il s'agisse de traiter quelques documents ou des milliers, IDP peut gérer efficacement la charge de travail. L'évolutivité de la technologie signifie qu'elle peut s'adapter à l'évolution des besoins de votre organisation sans expansion ou ajustement coûteux.
- Réduction des coûts grâce à l'automatisation. L'automatisation des flux de documents réduit le besoin de processus à forte intensité de main-d'œuvre et accélère les délais de traitement, ce qui contribue à des économies significatives. La rapidité et la précision de l'IDP améliorent également l'efficacité opérationnelle, ce qui a un impact positif sur vos résultats.
- Renforcer la conformité et la sécurité. Le maintien de la conformité réglementaire est essentiel dans tous les secteurs d'activité. MuleSoft IDP améliore la précision du traitement des données, garantissant que les informations sensibles sont traitées en toute sécurité et en conformité avec les normes du secteur, ce qui réduit les risques de conformité.
Comment fonctionne l'IDP de MuleSoft ?
Sous le capot, Mulesoft IDP exploite Amazon Textract pour extraire les données du document, tandis qu'Einstein AI se charge de l'analyse du contenu en fonction des invites fournies. Les informations extraites sont ensuite mises en forme dans un format structuré (par exemple, JSON) pour s'intégrer de manière transparente dans les flux de travail de votre entreprise.

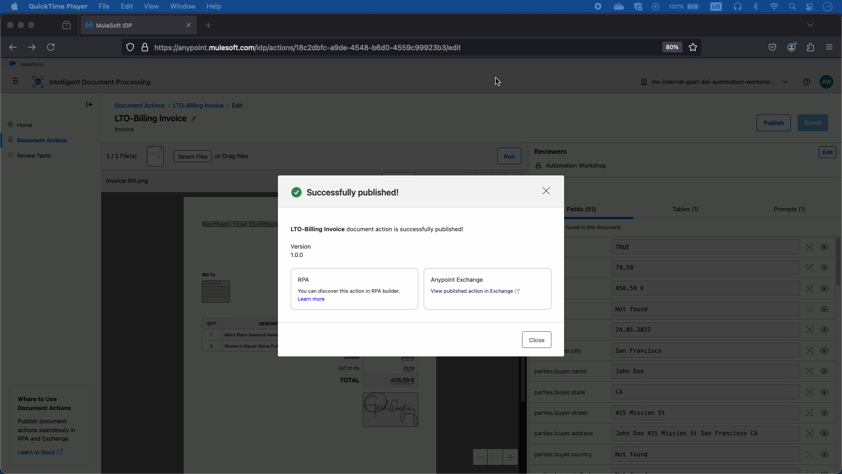
Les paramètres de configuration de ce processus sont appelés "actions de document", qui peuvent être personnalisées pour différents besoins d'extraction. Une fois configurée, l'action de document est publiée sur MuleSoft Exchange, où l'on peut y accéder via une API RESTful ou l'utiliser dans des applications comme Anypoint Studio ou RPA Builder pour une automatisation plus poussée.
Pour plus d'informations, veuillez consulter Intégrer IDP avec Anypoint Studio et et Automatiser le traitement des documents avec RPA.
En quoi cela diffère-t-il de ce qui existe déjà sur le marché ?
Les outils traditionnels de reconnaissance optique de caractères (OCR) ont été largement utilisés pour extraire des données de documents, mais ils nécessitent une sélection et une délimitation systématiques des zones du document avant l'extraction des données. Lorsqu'il s'agit de documents dynamiques dépourvus de modèle cohérent, les solutions de reconnaissance optique de caractères doivent être formées pour chaque modèle, ce qui nécessite une maintenance importante.
MuleSoft Intelligent Document Processing (IDP) va au-delà de l'OCR en utilisant l'analyse et l'extraction de documents par le biais d'un Large Language Model (LLM), un type d'Intelligence Artificielle (IA) formé pour identifier dynamiquement où se trouvent les informations souhaitées dans n'importe quel document. Cette approche nécessite moins de maintenance que l'OCR. Avec des requêtes cohérentes et concises, MuleSoft IDP peut localiser dynamiquement des informations sans configurer des zones de document spécifiques avant l'extraction.
À quoi cela ressemble-t-il ?
Démo : Traitement des factures
Grâce à MuleSoft IDP, les données sont extraites des factures en anglais, ce qui permet un traitement rapide et automatisé avec des options de révision manuelle lorsque la confiance dans l'extraction des données est faible.
Création et publication de l'action de document
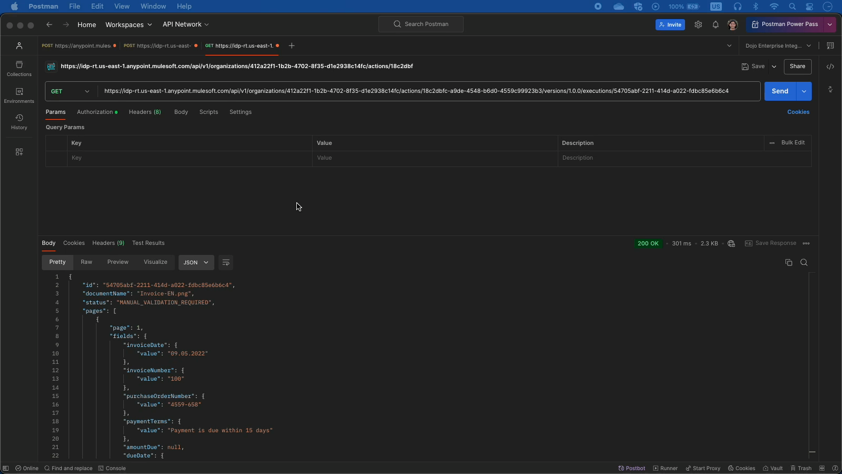
Visualisation de l'actif Exchange et appel de l'API via Postman
Déclenchement de l'examen manuel
Dans les cas où l'IDP n'est pas sûr des données extraites, un examen manuel peut être déclenché pour une vérification plus approfondie.
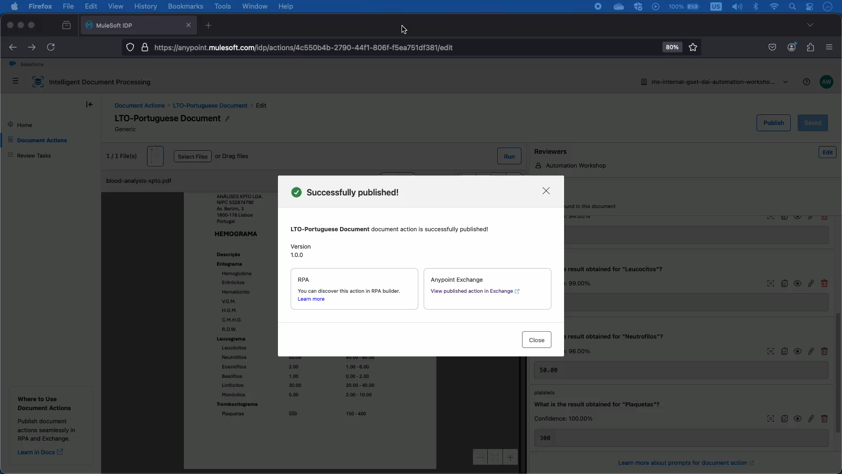
Démonstration : Traitement personnalisé des documents IDP peut traiter plusieurs langues, comme le montre l'extraction d'informations à partir de documents portugais, ce qui en fait une solution idéale pour les entreprises internationales ayant des besoins diversifiés en matière de documents.
Création et publication de l'action de document
Visualisation de l'actif Exchange et appel de l'API via Postman
Vous voulez en savoir plus ?
La solution de traitement intelligent des documents de MuleSoft apporte rapidité, précision et sécurité à vos flux de documents. Contactez-nous pour découvrir comment cette solution peut être mise en œuvre pour transformer les flux de travail de votre entreprise ou explorez nos services MuleSoft pour libérer le plein potentiel de MuleSoft pour votre organisation.
Contactez-nous dès aujourd'hui pour découvrir comment nous pouvons adapter les solutions Salesforce aux besoins uniques de votre entreprise.
Avertissement : Northern Trail Outfitters est une entreprise fictive utilisée dans cet article à des fins d'illustration.